- 研究成果
宇宙の大規模構造の複雑な統計パターンを高速予言する人工知能(AI)ツールを開発―宇宙ビッグデータのAI分析に向けて―

宇宙の基本的な枠組みを観測的に実証する分野である「観測的宇宙論」は、科学者が扱うことのできる最大スケールの実証科学として成熟してきました。この分野において、近年重要性が高まっているのが「宇宙の大規模構造」です。これは、個々の銀河が織り成す網状構造のパターンを指します。大規模構造は、宇宙がこれまでに経てきた複雑な進化の歴史の末の様子であり、すばる望遠鏡などを使ってこれを詳細に観測することで、宇宙の進化に影響を及ぼすダークマターやダークエネルギーの謎に迫ることができると期待されています。
私たちの宇宙はいったいどのような宇宙なのか。それを知るためには、さまざまな宇宙の大規模構造の進化をスーパーコンピュータを用いて物理理論に基づいて計算し、観測で得られたデータと照らし合わせることが極めて有効です。これには数十万から100万にも及ぶ宇宙論モデルの精巧な計算が必要となります。しかし、現在利用可能な最大の計算資源をもってしても、これほどの数のシミュレーションを行うことは困難です。
京都大学基礎物理学研究所の西道啓博特定准教授(兼・東京大学国際高等研究所カブリ数物連携宇宙研究機構 客員科学研究員)らの研究チームは、この困難に対して人工知能(AI)の一種である「機械学習」の方法を用いることで解決を試みました。「ダークエミュレータ」と名付けられた本研究グループの機械学習装置は、宇宙のダーク成分の量や性質などをさまざまに変えて計算した101のバーチャル宇宙から、それら対応関係を「学習」しました。これにより、新たなシミュレーションを行うことなく、新しい宇宙モデルに対して予想される観測結果の理論予言を高速に行うことを可能にしました。この学習に使われたバーチャル宇宙のデータは、国立天文台のスーパーコンピュータ「アテルイ」および「アテルイⅡ」を用いて約3年かけて計算された、総容量約300テラバイトにも及ぶ巨大シミュレーションデータです。ダークエミュレータは、銀河の空間分布や弱重力レンズ効果の実際の観測結果を、誤差2-3パーセント程度の精度で予言することが可能です。さらに、標準的なノートパソコンでも数秒以内に理論予言を行うことができ、計算コストをおよそ1億分の1に低減しました。
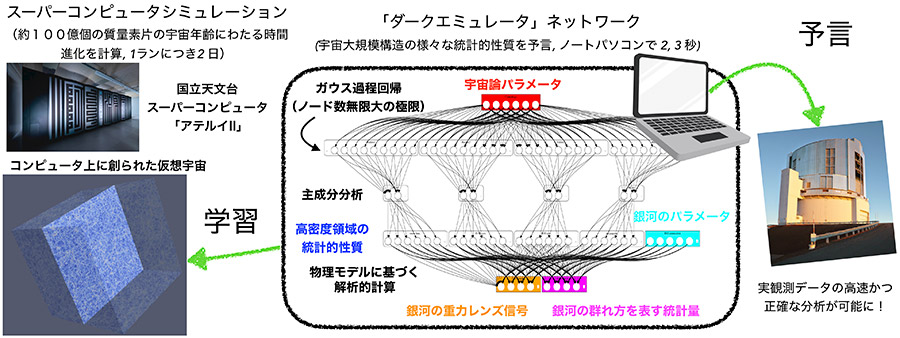
ダークエミュレータは実際の観測データに初めて直接応用可能なAIツールです。すばる望遠鏡の観測で取得した宇宙の大規模構造データの分析はもちろん、2020年代中盤以降に控える次世代の究極の宇宙論観測の時代における、AIを用いた宇宙ビッグデータ分析への着実な一歩と言えます。
この研究成果は、Nishimichi et al. “Dark Quest. I. Fast and Accurate Emulation of Halo Clustering Statistics and Its Application to Galaxy Clustering”として、米国の天体物理学専門誌『アストロフィジカル・ジャーナル』に2019年10月8日付けで掲載されました。
関連リンク
- 宇宙の大規模構造の複雑な統計パターンを高速予言する人工知能(AI)ツールを開発―宇宙ビッグデータのAI分析に向けて―(天文シミュレーションプロジェクト)
- 宇宙の大規模構造の複雑な統計パターンを高速予言する人工知能(AI)ツールを開発―宇宙ビッグデータのAI分析に向けて―(京都大学)
- 宇宙の大規模構造の複雑な統計パターンを高速予言する人工知能(AI)ツールを開発―宇宙ビッグデータのAI分析に向けて―(京都大学基礎物理学研究所 )
- 宇宙の大規模構造の複雑な統計パターンを高速予言する人工知能(AI)ツールを開発―宇宙ビッグデータのAI分析に向けて―(東京大学国際高等研究所カブリ数物連携宇宙研究機構)